夢瑤 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
壞了,阿里這波是沖著Sora 2去的!
剛剛,阿里發(fā)布了新一代通義萬相2.6系列模型,一次性覆蓋文生視頻、圖生視頻、參考生視頻,以及圖像生成和文生圖,是目前全球功能最全的視頻生成模型。
在視頻創(chuàng)作上,萬相2.6不僅推出了Sora2目前還沒有的多音頻驅(qū)動生視頻能力,還同步引入了音畫同步、多鏡頭敘事等能力。
像下面這個超火的一刀切ASMR,就是通過文本+音頻直接驅(qū)動出來的:
再看這個由文本+圖像+音頻驅(qū)動的小貓沉浸式吃播,咀嚼聲和嘴部動作基本能卡在點上,吃得那叫一個香:
文生圖這條線也同步補(bǔ)強(qiáng)了,萬相2.6在藝術(shù)風(fēng)格控制、真實感人像、中英文長文本生圖以及歷史文化IP語義理解等方面的創(chuàng)作能力也都有明顯提升,效果be like:

本著啥都測測的原則,我也專門用不同Prompt和參考素材實測了一輪,總的來說:
萬相2.6在音視頻參考、聲畫同步、風(fēng)格理解方面表現(xiàn)確實不錯,但在個別場景下仍會出現(xiàn)畫面邏輯偏差的小問題,不過對日常短視頻和二創(chuàng)來講,已經(jīng)是可用且好用的水平了。
模型到底表現(xiàn)如何,咱們邊嘮邊測~
視頻生成能力一手實測
實測之前,我先幫大家快速捋一下這次萬相2.6在視頻生成上的幾個核心升級點:
視頻參考生成:支持視頻參考,模型能提取其中主體的外觀與音色,并結(jié)合提示詞生成新視頻內(nèi)容,可用于單人表演或雙人合拍等場景。
多鏡頭敘事:支持多鏡頭生成,保持鏡頭間關(guān)鍵信息一致,可通過簡單提示詞完成分鏡。
自然聲畫同步:在多人對話等復(fù)雜場景中,語音與動作匹配更穩(wěn)定。
15s長視頻生成:單條視頻最長15秒(參考生視頻最長10秒)。
基礎(chǔ)能力提升:在指令理解與執(zhí)行、畫面真實度及整體美學(xué)表現(xiàn)等方面均有加強(qiáng)。
嘖嘖嘖,說實話這次更新的能力維度確實蠻多,模型到底能不能打,咱們一一測測看!!!

先來測這次升級中我自認(rèn)為最大的看頭——視頻參考生成功能。
這不最近快到年底了,各路短視頻主播都在摩拳擦掌準(zhǔn)備沖一波年終銷量,我索性腦洞一開,直接把一段梵高的視頻喂給了萬相2.6,讓梵高也趁年底一起沖一波KPI!
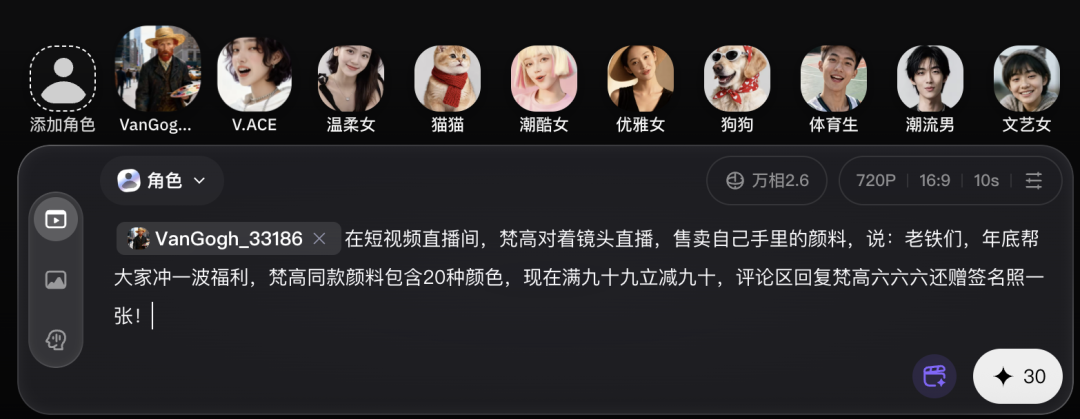
咱從主體一致性和聲音一致性兩個點來看效果。
整體表現(xiàn)是值得肯定的,萬相2.6在視頻主體一致性和提示詞理解上確實做得比較扎實,梵高形象基本實現(xiàn)了1:1還原,口型匹配也較為準(zhǔn)確,人物的動作、表情與臺詞語義能夠?qū)?yīng)得上,整體觀感比較完整~
唯一的小瑕疵在聲音上,生成結(jié)果中的聲線并沒有完全沿用原視頻,有點AI自由發(fā)揮的意思。
咱們再來試試聲畫同步能力,最近二創(chuàng)兵馬俑的AI玩法視頻超級火,咱這次直接給萬相2.6上點難度,讓它roll一段雙人劇情演繹的兵馬俑對話小視頻,看看效果咋樣!
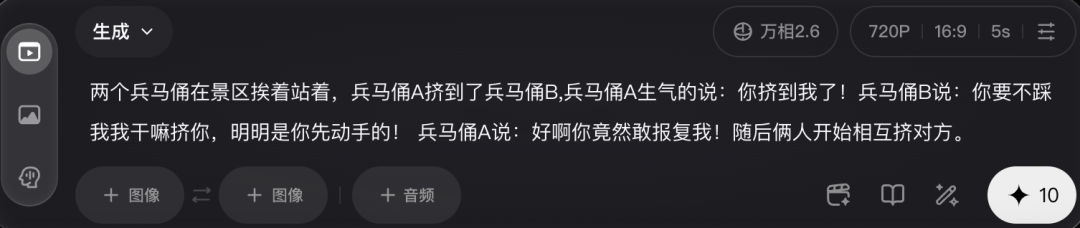
從下面生成的效果看,確實喜感滿滿,兩尊兵馬俑在相互推搡的同時進(jìn)行對話,動作與語言形成了較為完整的互動。
頗有趣味的是,兩尊兵馬俑一邊推搡一邊對話,動作和語言形成了完整互動,更關(guān)鍵的是,模型不僅補(bǔ)全了臺詞,還加了和動作匹配的擬聲細(xì)節(jié),并能區(qū)分不同角色的情感變化,“憤怒感”的情緒還是立得住的~
再來玩點有意思的,這回我給了萬相2.6一段小貓小狗對話的臺詞,讓它幫我生成一段相聲表演,效果be like:
整體來講,聲畫同步效果確實做到位了,但也暴露了一些小bug:比如小貓說了本該是小狗的臺詞,最后一個鏡頭字幕和語音沒完全對齊,模型在多角色綁定上還有提升空間。
除了音視頻參考和聲畫同步能力外,萬相2.6在畫面質(zhì)感和美學(xué)呈現(xiàn)方面也有了不少提升,比如下面這段我生成的第一人稱賽博城市飛行視角的視頻:
第一人稱視角,無人機(jī)高速飛行視角,夜晚賽博朋克城市,密集高樓林立,霓虹燈與全息廣告在兩側(cè)快速掠過。鏡頭低空穿行于城市街道與高架之間,連續(xù)急轉(zhuǎn)彎、俯沖與拉升動作,掠過懸浮屏幕、樓宇天橋與空中管線。城市燈光在鏡頭邊緣產(chǎn)生運(yùn)動模糊,玻璃幕墻反射出飛行軌跡,雨后路面泛起冷色反光。整體節(jié)奏緊湊、速度感強(qiáng),畫面穩(wěn)定但具有真實飛行慣性,科幻感強(qiáng)烈,偏冷色調(diào),高對比度,電影級畫面質(zhì)感。
從視頻生成效果看,飛行視角、快速掠過、急轉(zhuǎn)彎、俯沖拉升這些關(guān)鍵詞都呈現(xiàn)到位了,而且確實賽博感滿滿,有點末日大片的感覺,看來這AI還是有點美學(xué)天賦的。
最后我們來測一把萬相2.6的多鏡頭敘事能力,這次我交代給AI的任務(wù)是讓它生成一個包含3個鏡頭的多動作劇情視頻:

從生成效果來看,萬相2.6對多鏡頭敘事的理解較為到位,三個鏡頭中的主要動作和轉(zhuǎn)場均得到了完整呈現(xiàn),鏡頭之間的銜接也相對自然,并未出現(xiàn)明顯生硬的跳切。
但由于提示詞中對具體場景描述不夠充分,像「探頭觀察」這類較為抽象的動作,對模型來說仍存在一定理解難度,以至于大家會發(fā)現(xiàn)視頻中的男子是對著墻面觀察的,還是有點不太符合正常人的動作邏輯,大家在寫多鏡提示詞時可以多給AI一些補(bǔ)充信息~
圖片美學(xué)也上了一個level
除了視頻能力外,這次萬相2.6在圖片生成功能在美學(xué)理解、人像生成、文字處理、歷史文化&知識ip語義理解上也帶來了一些新升級。
咱們先來說說風(fēng)格化能力,其實風(fēng)格化生成對于AI來說不是難事,但難就難在AI能不能及時掌握一些新的美學(xué)風(fēng)格。
最近我在社交軟件上刷到星露谷風(fēng)格插畫很火,我們也讓萬相2.6做個同款風(fēng)格的插畫看看效果~
星露谷風(fēng)格,地鐵上坐滿站滿了各種打工人,有的人忙著用電腦打字,有的人忙著打電話,有的忙著聽音樂等等,展現(xiàn)出不同的車廂人物狀態(tài)。

高飽和的色塊拼接、稍許像素風(fēng)的處理確實有星露谷內(nèi)味兒了,而且還有點像最近短視頻特火的蒸汽波風(fēng)插畫vlog~
再來試試「人像生成」能力,官方介紹說這次萬相2.6在人像光影方面的處理也更好了,我們來roll一把!
年輕男性半身人像,室內(nèi)窗邊場景。側(cè)前方自然光照亮面部,明暗過渡柔和,輪廓立體;背景壓暗,膚質(zhì)真實,電影級攝影光影質(zhì)感。

整體生成效果不錯,光影表現(xiàn)是亮點。側(cè)窗光形成了清晰的明暗分區(qū),面部結(jié)構(gòu)被很好地勾勒出來,膚質(zhì)細(xì)節(jié)自然,沒有明顯過度磨皮,畫面還是有較強(qiáng)的電影感和空間層次的~
最后再來淺淺測一下中英文處理能力,咱們直接讓萬相2.6生成一個中英文對照排版的美食宣傳海報!
中式餐廳宣傳海報,縱向構(gòu)圖,中英文排版,海報主體為一碗熱氣騰騰的招牌菜,背景干凈。海報文字內(nèi)容如下:中文主標(biāo)題:“招牌牛肉面”,英文副標(biāo)題:“Signature Beef Noodles”,中文副文案:“每日現(xiàn)熬湯底 · 新鮮食材”,英文副文案:“Fresh ingredients, slow-cooked broth”文字排版清晰,中文在上,英文在下,層級分明,整體風(fēng)格溫暖、有食欲感,適合餐廳宣傳海報。

其實對于這張圖而言,最難的不是中英文生成,而是構(gòu)圖排版,對于美食海報來說,主體占比最大的一定是食物本身,從輸出效果看,模型在美學(xué)判斷上是靠譜的,這一張已經(jīng)完全達(dá)到成品水準(zhǔn)。
這波整體測下來,萬相2.6給我的最直觀的感受就是:有小瑕疵,但是整體表現(xiàn)還不錯的。
畢竟,有些地方它確實還會犯迷糊,比如多角色臺詞偶爾對不上、復(fù)雜動作理解有時不到位,但聲畫同步、視頻參考這些核心能力已經(jīng)挺穩(wěn)了。
至少對我這種平時做點視頻、二創(chuàng)、測試玩法的人來說,這一代已經(jīng)是敢多跑幾次、不用每次都碰運(yùn)氣的狀態(tài)了。
除了剛才測到的一些能力外,萬相2.6在多圖融合、美學(xué)要素遷移、歷史知識語義理解上也做了提升,感興趣的朋友可以直接去官網(wǎng)試試~
一鍵三連「點贊」「轉(zhuǎn)發(fā)」「小心心」
歡迎在評論區(qū)留下你的想法!
—?完?—
專屬AI產(chǎn)品從業(yè)者的實名社群,只聊AI產(chǎn)品最落地的真問題
掃碼添加小助手,發(fā)送「姓名+公司+職位」申請入群~

進(jìn)群后,你將直接獲得:
最新最專業(yè)的AI產(chǎn)品信息及分析
不定期發(fā)放的熱門產(chǎn)品內(nèi)測碼
內(nèi)部專屬內(nèi)容與專業(yè)討論
點亮星標(biāo)
科技前沿進(jìn)展每日見

