近日,小米發(fā)布并開源了最新MoE大模型MiMo-V2-Flash。老實說,當看到“309B參數(shù)”這個數(shù)字時,下意識的反應是:也不是太大呀。

但如果我們把目前主流的開源模型按總參數(shù)量畫一個金字塔,那么MiMo-V2-Flash (309B) 也處于塔第一梯隊:DeepSeek-V3/R1: 總參數(shù) 671B(MoE架構(gòu));Llama 3.1 405B: 總參數(shù) 405B(稠密模型);Grok-1: 總參數(shù) 314B(MoE架構(gòu));Qwen3:總參數(shù)235B激活參數(shù)22B (MoE)。
而細看“激活參數(shù)15B”,那股熟悉的“小米味兒”立馬就回來了。
雖然羅福莉在演講時說到了MiMo-V2-Flash在代碼和Agent測評基準測試中的表現(xiàn),但核心還是那句“極致推理效率”。AI資本局認為,MiMo-V2-Flash不是一個為了在榜單上刷分、或者為了寫詩作畫而生的模型。這是一個帶著點“過日子”精打細算的工程產(chǎn)物。在如今言必稱“AGI”的宏大敘事里,小米這步棋走得很像當年的紅米手機——不談星辰大海,先讓你用得起、跑得動。
309B的外殼,15B的心跳
MiMo-V2-Flash 這個架構(gòu)很有意思。總參數(shù)3090億,保證了它的“腦容量”,知識覆蓋面夠廣;但干活的時候,每次只調(diào)動150億參數(shù)。就像雇了一個擁有300人智庫的機構(gòu),但平時處理具體任務時,只派最懂行的15個人出面。
為什么要這么做?為了速度和成本。
對于賣手機、賣車的小米來說,“反應慢”是致命的。想象一下,你開著小米SU7,喊一聲“幫我規(guī)劃路線”,如果車機要反應3秒鐘才能回答,你可能早就錯過路口了。
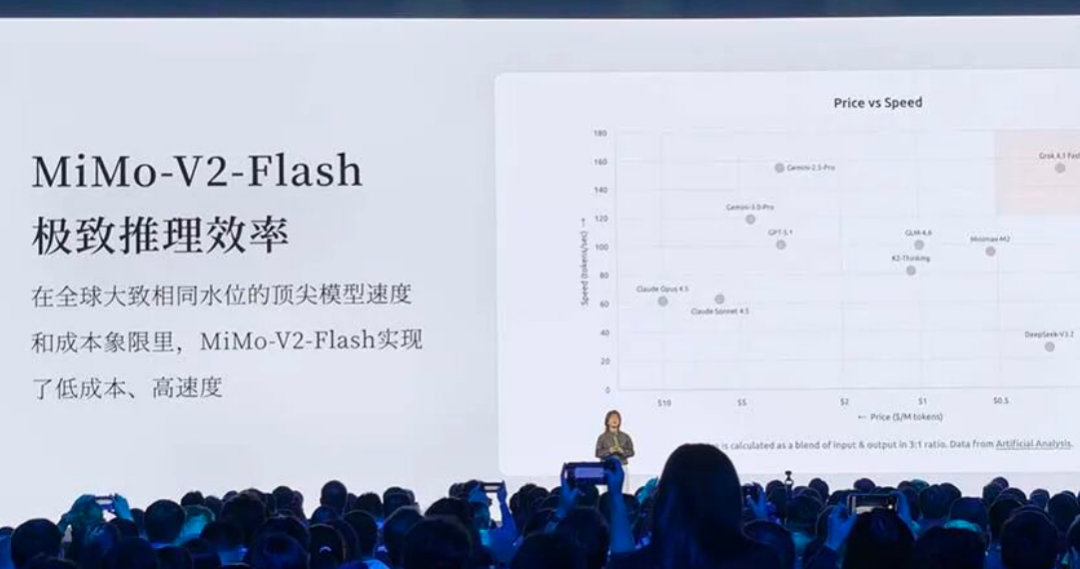
15B的激活參數(shù),恰好卡在高性能邊緣計算和低成本云端推理的“甜點區(qū)”,Qwen用在AI眼鏡上的模型,也在這個區(qū)間。它比純粹的端側(cè)小模型要聰明,又足夠快,所以叫Flash。小米要的不是一個高高在上的“智者”,而是一個能塞進車機、塞進手機助手里,甚至未來塞進機器人里的“熟練工”。
醉翁之意不在“聊”,在“OS”
很用戶看大模型,盯著看它能不能寫代碼、能不能寫周報。但對小米來說,MiMo-V2-Flash的戰(zhàn)場不在聊天框里。
雷軍現(xiàn)在手里的牌是“人車家全生態(tài)”。這個生態(tài)最缺的是什么?是粘合劑。
以前的智能家居和車機,所謂的“智能”其實是“指令集”——你得按特定的句式說話它才聽得懂。而大模型是用來把這些硬件變成“Agent”的。
小米這次特意強調(diào)了“Agent場景”和“代碼能力”以及物理世界感知,這非常關鍵。這意味著在這個模型眼里,你的手機不僅僅是一個問答機器,而是一個能調(diào)用APP、能操作系統(tǒng),且能夠跟物理世界直接交互的工具人。
DeepSeek也好,Qwen也好,它們在通用領域很強,但它們還沒有硬件入口。小米有數(shù)以億計的手機和50萬臺在路上跑的小米汽車,它需要一個自家的、可控的、成本極低的模型來接管這些設備的底層交互,這樣大模型在操作系統(tǒng)層面的“全天候待機”才有經(jīng)濟上的可能性。
雷軍為何選擇開源?
最后說說開源。小米為什么要把這么大的模型開源?
AI資本局認為,除了“技術(shù)自信”這種場面話,更深層的原因是:焦慮。
在國內(nèi),阿里千問和DeepSeek在開源社區(qū)的統(tǒng)治力太強了。開發(fā)者習慣了用Qwen微調(diào),習慣了DeepSeek的生態(tài),這對小米的HyperOS生態(tài)是個威脅。如果未來的AI原生應用都是基于別人的基座開發(fā)的,小米在系統(tǒng)層面的話語權(quán)就會被稀釋。
把MiMo-V2-Flash開源,是在向開發(fā)者喊話:“來我這兒玩,我的模型雖然大,但推理便宜,而且完美適配小米的硬件。”這是在爭奪未來AI應用的“定義權(quán)”。
所以,小米發(fā)布的大模型不是一個用來“炫技”的藝術(shù)品,MiMo-V2-Flash雖然號稱對標Claude Sonnet 4.5,但肯定不是全世界最聰明的模型,不過它一定是最適合小米當前商業(yè)邏輯的模型。
在別的廠商還在比拼誰的模型更像“神”的時候,小米做了一個更像“人”的決定:把價格打下來,把速度提上去,然后把它塞進你生活的每一個縫隙里。
這很雷軍,也很小米。



