金磊 發(fā)自 凹非寺
量子位 | 公眾號 QbitAI
上市后的僅15天,?摩爾線程,便將首個大動作直接指向了生態(tài)的核心——開發(fā)者。
在這次首屆、也是國內(nèi)首個聚焦全功能GPU的開發(fā)者大會中,圍繞著MUSA這個關(guān)鍵詞,新品可謂是目接不暇:
一個全新GPU架構(gòu):花港,密度提升50%,效能提升10倍。
三款新芯片:華山、廬山、長江,分別聚焦AI訓推一體、圖形渲染和智能SoC。
一個智算集群:夸娥萬卡集群(KUAE2.0),定位國產(chǎn)自主研發(fā)的AI Foundry。
兩款硬件產(chǎn)品:專為開發(fā)者打造的AIBOOK和AICube。
這并非零散的產(chǎn)品更新,而是摩爾線程用一套從云到端、從算力到生態(tài)的組合拳。

在長達2個多小時的發(fā)布中,最直觀的感受就是,摩爾線程,已經(jīng)把國產(chǎn)GPU推向了下一個level。
接下來,我們就從最最最核心的全新GPU架構(gòu)花港為起點,對此次開發(fā)者大會一探究竟。
MUSA,已經(jīng)成了全功能GPU架構(gòu)的代名詞
什么是MUSA?
它的全名叫做Meta-computing Unified System Architecture,是摩爾線程自主研發(fā)的元計算統(tǒng)一計算架構(gòu)。
該怎么理解?可以說,從芯片架構(gòu)、指令集、編程模型,到軟件運行庫及驅(qū)動程序框架,都屬于MUSA的范疇。

歷經(jīng)五年的發(fā)展,MUSA已經(jīng)完整定義了全功能GPU從芯片設(shè)計到軟件生態(tài)的統(tǒng)一技術(shù)標準,并且支持AI計算、圖形渲染、物理仿真和科學計算、超高清視頻編解碼等全場景高性能計算。
若是縱觀MUSA硬件架構(gòu)這幾年的迭代,從蘇堤、春曉、曲院,再到平湖,每一次的升級都是在探索著GPU算力的邊界。
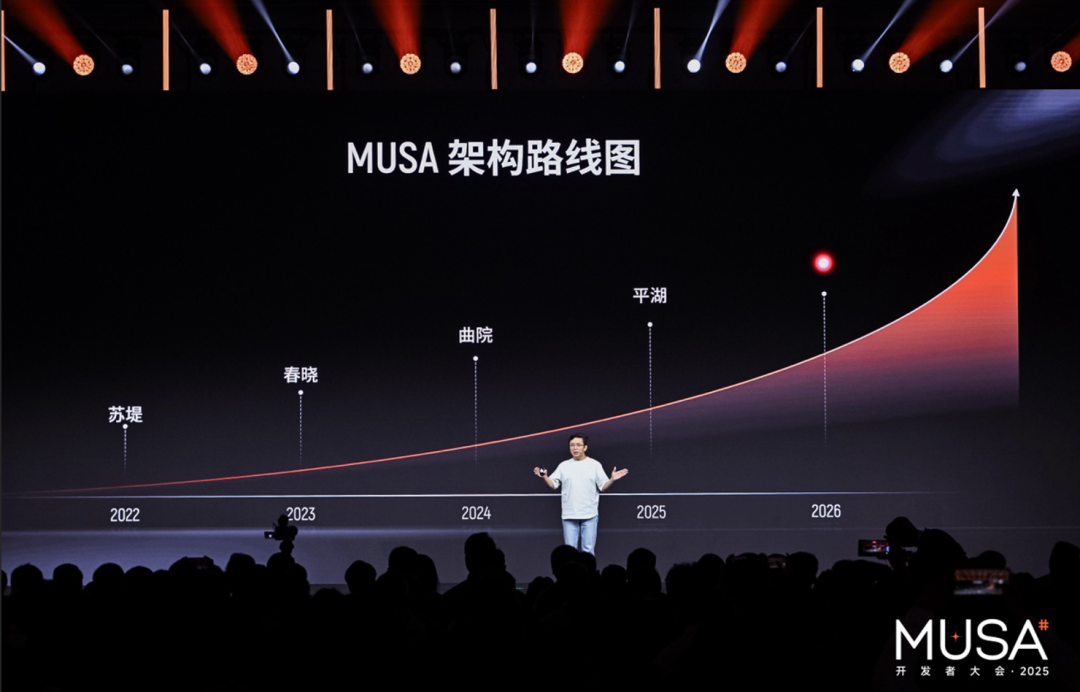
最新發(fā)布的第五代全功能GPU架構(gòu)花港,亦是如此:
算力密度提升50%:在同等芯片面積下,可部署更多計算單元;
計算能效提升10倍:單位瓦特性能大幅優(yōu)化,為大規(guī)模智算集群提供綠色底座;
新增FP4計算:從FP4、FP6、FP8到FP16、BF16乃至FP64,實現(xiàn)全精度端到端計算,覆蓋AI、HPC、圖形等全場景需求;
支持十萬卡集群:通過MTLink高速互聯(lián),為超大規(guī)模模型訓練鋪平道路。
尤為值得關(guān)注的是,花港在低精度計算上的深度優(yōu)化。架構(gòu)新增了MTFP6/MTFP4及混合低精度端到端加速技術(shù),專為未來AI主流場景——低比特訓練與推理而生。
在Attention機制的關(guān)鍵路徑上,花港原生支持矩陣rowmax計算,大幅提升混合精度SIMT吞吐量,并內(nèi)置在線量化/反量化、隨機舍入等硬件加速能力,為下一代Transformer引擎(如MT Transformer Engine)提供底層支撐。

如果說硬件架構(gòu)是能力的基石,那么軟件棧,就是將這些能力交到開發(fā)者手中的具體路徑。
除了架構(gòu)本身之外,摩爾線程這次還同步推出了MUSA軟件棧5.0,構(gòu)建從編譯器、算子庫到AI框架的全棧工具鏈:
AI框架廣泛適配:除PyTorch、PaddlePaddle外,新增對JAX、TensorFlow的支持;
訓練生態(tài)擴展:在Megatron、DeepSpeed基礎(chǔ)上,新增強化學習訓練框架MT VeRL;
推理引擎豐富:深度優(yōu)化自研MTT推理引擎與TensorX,同時適配SGLang、vLLM、Ollama等新興推理框架;
核心庫極致優(yōu)化:muDNN實現(xiàn)GEMM/FlashAttention效率超98%,通信效率達97%,編譯器性能提升3倍;
編程語言創(chuàng)新:推出面向AI+渲染融合的muLang,兼容TileLang、Triton,原生支持MUSA C,并發(fā)布GPU中間表示語言MTX 1.0,提升開發(fā)者調(diào)優(yōu)自由度。
更關(guān)鍵的是,摩爾線程宣布將逐步開源MATE算子庫、MUTLASS、MT DeepEP通信庫、KUAE云原生工具包等核心組件,向開發(fā)者社區(qū)開放底層能力,加速生態(tài)構(gòu)建。
不難看出,MUSA并未將自身定位為單純的AI加速器,而是以“全功能 GPU”為錨點,將 AI 能力深度嵌入圖形渲染、物理仿真、量子計算等高價值垂直場景。
這種從通用底座向產(chǎn)業(yè)縱深延伸的架構(gòu)哲學,使其區(qū)別于純粹的大模型訓練卡,而更接近英偉達 CUDA 生態(tài)早期“以通用可編程性撬動多元應(yīng)用”的戰(zhàn)略路徑。
可以說,MUSA 不僅是中國首個全功能GPU架構(gòu),更是對“下一代 AI 基礎(chǔ)設(shè)施應(yīng)長什么樣”的一次系統(tǒng)性回答——
它不再只是算力的提供者,而是多模態(tài)智能、具身智能乃至物理AI時代的關(guān)鍵使能平臺。在這一意義上,摩爾線程的架構(gòu)創(chuàng)新,已不僅是技術(shù)突破,更是對未來 AI 產(chǎn)業(yè)格局的一次主動定義。
而圍繞著新升級的MUSA,摩爾線程這次還祭出了更多重磅產(chǎn)品。
三個新芯片,兩個新硬件,一個萬卡集群
首先基于花港架構(gòu),摩爾線程發(fā)布了兩款芯片路線。
第一個便是聚焦在AI訓推一體及高性能計算的GPU——華山。

它的核心亮點可以總結(jié)為:
全精度支持:從 FP4 到 FP64,覆蓋低精度訓練與高精度科學計算;
MTFP4/MTFP6 混合低精度加速:Attention 計算從 BF16 向 FP8 甚至 FP6 演進,大幅提升 Transformer 吞吐;
硬件級優(yōu)化:原生支持矩陣 rowmax 計算、在線量化/反量化、隨機舍入等算法,專為大模型訓練定制;
新一代異步編程模型:支持常駐核函數(shù)、線程束特化,極大提升并行效率。
并且從浮點算力、訪存寬帶、訪存容量和高速互聯(lián)寬帶等維度來看,華山正在追趕英偉達的系列產(chǎn)品。

華山的推出,標志著摩爾線程正式具備支撐萬億參數(shù)大模型訓練的能力,為國產(chǎn)AI基礎(chǔ)設(shè)施補上關(guān)鍵一環(huán)。
如果說華山主攻A 算力,那么接下來的GPU——廬山,則專為圖形計算而生。

相比上一代產(chǎn)品,其AI計算性能提升了驚人的64倍,3A游戲渲染性能提升15倍。
廬山引入了AI生成式渲染架構(gòu)(AGR)和硬件光追引擎,支持DirectX 12 Ultimate。這意味著,國產(chǎn)顯卡正式邁入“光追+AI渲染”的新范式,不僅僅是“算”畫面,更是“生成”畫面。
除此之外,在端側(cè),摩爾線程還首次推出了智能SoC芯片——長江。

據(jù)了解,長江芯片不局限于傳統(tǒng)PC或服務(wù)器,而是面向具身智能、車載、AI計算終端等端側(cè)場景,提供50 TOPS的異構(gòu)AI算力。
有了芯片,自然要有承載的載體。
基于長江芯片,摩爾線程這次還發(fā)布了兩個非常亮眼的硬件產(chǎn)品。
首先就是MTT AIBOOK。
這個算力本是專門為AI學習與開發(fā)者打造的個人智算平臺,運行基于Linux內(nèi)核的MT AIOS操作系統(tǒng),具備多系統(tǒng)兼容能力,并預(yù)置完整AI開發(fā)環(huán)境與工具鏈,通過虛擬化和安卓容器,可無縫運行Windows與安卓應(yīng)用。
如此一來,你就可以直接在上面跑大模型、搞Agent開發(fā)。

MTT AIBOOK內(nèi)置的智能體小麥,還支持2K高清渲染、本地大模型(如 MUSAChat-72B)、端側(cè) ASR/TTS,這就讓它從工具變成了超級個體助手。

并且MTT AIBOOK還預(yù)裝了智源悟界Emu3.5多模態(tài)模型,開箱即可文本生圖、編輯圖像。
除此之外,針對端側(cè)場景,摩爾線程還推出了桌面上的AI小鋼炮——AICube。
它更像是一個高性能的AI計算魔方,讓開發(fā)者在桌面上就能輕松獲取算力支持,處理復雜的推理任務(wù)。

最后,也是最重磅的——夸娥(KUAE 2.0)萬卡智算集群;畢竟在大模型領(lǐng)域,萬卡集群是公認的入場券。
摩爾線程此次宣布,其萬卡集群在Dense大模型上的算力利用率(MFU)達60%,在MOE大模型上達40%,有效訓練時間占比超過90%。
最硬核的消息是:摩爾線程已完整復現(xiàn)了DeepSeek V3的FP8訓練。 依靠S5000對低精度算子的優(yōu)化,其自研FP8 GEMM算力利用率高達90%。

在這次大會上,摩爾線程還前瞻性地披露了下一代高密硬件基石——MTT C256超節(jié)點。
這款產(chǎn)品采用了計算與交換一體化的高密設(shè)計。它的出現(xiàn),是為了系統(tǒng)性地提升萬卡集群在超大規(guī)模智算中心里的能效比和訓練效能。

這個量級的表現(xiàn),意味著它已經(jīng)具備了正面硬剛國際主流Hopper架構(gòu)AI GPU的底氣,是未來超大規(guī)模大模型訓練和實時推理的國產(chǎn)標準答案。
并且就在最近,摩爾線程還和硅基流動(SiliconFlow)聯(lián)合宣布:
基于硅基流動高性能推理引擎,雙方已在摩爾線程MTT S5000 GPU上成功完成對DeepSeek V3 671B滿血版大模型的深度適配與性能驗證。
在FP8低精度推理技術(shù)加持下,MTT S5000單卡實測Prefill吞吐突破4000 tokens/s,Decode吞吐超1000 tokens/s,創(chuàng)下當前國產(chǎn)GPU在大模型推理場景下的新高。
這一成果不僅刷新了國產(chǎn)GPU的推理性能基準,更傳遞出一個關(guān)鍵信號:
在成熟軟件工程體系(如MUSA架構(gòu)與硅基流動推理引擎)的協(xié)同優(yōu)化下,國產(chǎn)算力硬件正從“能跑”邁向“跑得快、跑得穩(wěn)、跑得值”。
換句話說:單位算力的有效利用率,正在成為國產(chǎn)AI芯片真正落地的關(guān)鍵指標——而摩爾線程,這次交出了一份高分答卷。
生態(tài),生態(tài),還得看生態(tài)
在全球算力競爭日益白熱化的今天,單一芯片的性能優(yōu)勢已不足以構(gòu)建護城河。
真正的壁壘,在于軟件生態(tài)、硬件協(xié)同、場景落地與開發(fā)者信任的綜合能力。
摩爾線程深諳此道,它的選擇也非常清晰:不走局部替代路線,而是以“MUSA架構(gòu)+國產(chǎn)GPU+全場景產(chǎn)品”三位一體,打造一個從底層指令集到上層應(yīng)用的完整生態(tài)閉環(huán)。
這不僅包括人才生態(tài),更涵蓋繁榮的軟件開發(fā)生態(tài)——從自研編譯器、高性能算子庫,到對主流AI框架的廣泛適配,摩爾線程提供了釋放算力所需的全套軟件工具鏈;同時,通過AIBOOK等面向開發(fā)者的硬件入口產(chǎn)品,讓開發(fā)者能夠隨時隨地接入并高效使用MUSA算力,真正實現(xiàn)軟硬協(xié)同、端云一體的全場景覆蓋。
但除此之外,開發(fā)者和開發(fā)生態(tài),亦是其中非常關(guān)鍵的一環(huán)。
這便是摩爾線程打造摩爾學院(MUSA開發(fā)者的成長平臺)的原因了。

截止2025年12月,摩爾學院已經(jīng)匯聚了20萬名開發(fā)者。摩爾線程的目標更宏大:培育百萬規(guī)模的MUSA開發(fā)者社群。
為此,他們不僅提供了從入門到大師的專業(yè)課程,還把根扎到了人才源頭——走進全國200所高校。通過產(chǎn)教融合、聯(lián)合實驗室以及“繁星計劃”等競賽,摩爾線程正在從象牙塔開始,培養(yǎng)屬于自己的、懂國產(chǎn)架構(gòu)的原生代開發(fā)者。
這也印證了中國工程院院士、清華大學計算機系教授鄭偉民的觀點:“國產(chǎn)GPU的關(guān)鍵,在于要從能跑到愿意用。”
整體來看,當別人還在爭論“國產(chǎn) GPU 能不能用”時,摩爾線程已經(jīng)通過從軟件棧工具、硬件入口到人才培育的全鏈路布局,讓開發(fā)者問出另一個問題:“我的下一個項目,能不能全在 MUSA 生態(tài)里完成?”
這,或許才是真正的突破。
一鍵三連「點贊」「轉(zhuǎn)發(fā)」「小心心」
歡迎在評論區(qū)留下你的想法!
—?完?—
點亮星標
科技前沿進展每日見



